#从 LUFFY 看 reasoning SFT 的 off-policy 问题:从“背高手答案”到在学生分布上学习
这篇文章以 Learning to Reason under Off-Policy Guidance / LUFFY(arXiv:2504.14945)为锚点,讨论一个现在 reasoning post-training 里越来越核心的问题:我们到底应该怎样使用强模型生成的长推理轨迹?
一句话结论是:
reasoning SFT 的 off-policy 问题,本质不是“teacher 的 CoT 写得好不好”,而是“teacher 的中间决策轨迹是否落在 student 自己会访问、能吸收、能修复的状态分布上”。LUFFY 之后的研究趋势,正在从“直接模仿强模型 trace”转向“让 student 自己 rollout,然后在 student-visited states 上接受 teacher / verifier / reward 的密集指导”。
更人话一点:
不要让学生死背职业棋手的整盘复盘;应该让学生先下出自己会下的局面,再让高手在这些局面里指出哪里能走、哪里该回退、哪些选择值得保留。
#1. 锚点:LUFFY 到底指出了什么问题?
LUFFY 的论文链接:<https://arxiv.org/abs/2504.14945>。我之前已经单独写过一篇论文详解: LUFFY 论文详解。这里不重复所有细节,而是把它放在更大的研究脉络里看。
LUFFY 面对的是 reasoning RLVR 中的两难:
- 纯 on-policy RLVR:模型只能从自己采样出来的解法里学习。如果 base model 太弱,采样不到正确轨迹,verifiable reward 就全是 0,训练启动不了。
- 朴素 reasoning SFT / Think SFT:直接拿 DeepSeek-R1、o1 类强模型的长 CoT 来教弱模型。看起来有监督信号,但 student 学到的可能只是强模型的表面话术、长度模式和反思格式,而不是自己可执行的推理策略。
LUFFY 的解决方式不是否定 off-policy trace,而是改变使用方式:把 off-policy reasoning traces 放进 RLVR 的 mixed-policy training 中,与 student 的 on-policy rollouts 一起计算 group advantage,再用 policy shaping 避免僵硬模仿。
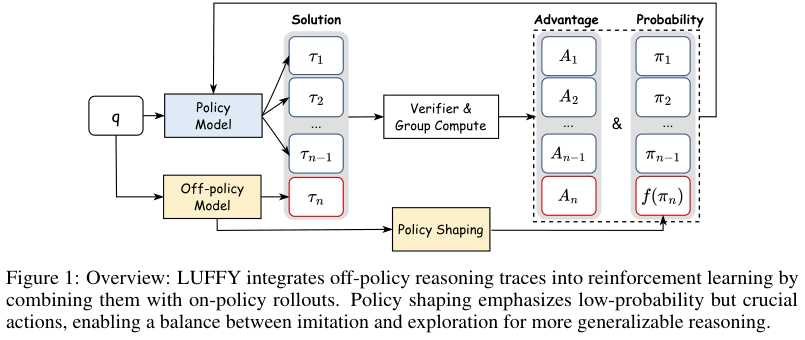
LUFFY 的一个重要证据是:朴素 SFT 虽然能把模型输出拉长、拉得更像 DeepSeek-R1,但泛化并不好。论文报告中,SFT 的平均生成长度达到 4646 tokens,LUFFY 是 2832 tokens;SFT 与 DeepSeek-R1 trace 的 BLEU 相似度达到 57.5,而 LUFFY 是 44.8。这说明 SFT 更像是在复制 teacher 的轨迹形状,LUFFY 则更像是在选择性吸收。
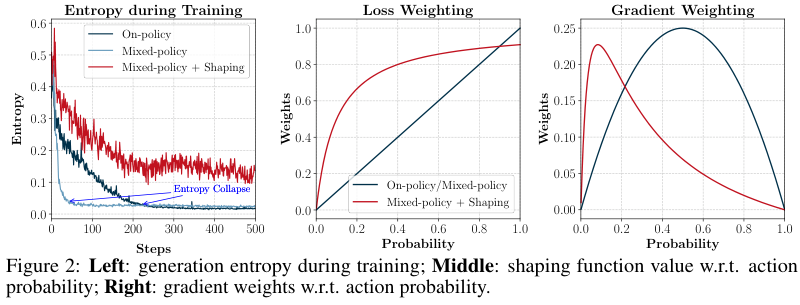
所以 LUFFY 给这个方向留下的核心问题是:
off-policy guidance 明明有价值,但为什么直接 SFT 不够?如果 SFT 不够,后续该怎样把 teacher trace、student rollout、verifier reward、process feedback 组织起来?
#2. 为什么 reasoning SFT 比普通 SFT 更容易 off-policy?
普通 SFT 教的是“输入 -> 输出”。例如用户问一个问题,模型学一个回答。它当然也有 exposure bias,但通常输出本身就是目标。
reasoning SFT 不一样。它教的是:
问题 -> <think> 中间推理 / 反思 / 回退 / 验证 / 搜索轨迹 </think> -> 答案
这里 <think> 不是普通文本,而是一条决策过程轨迹。每一步推理都会改变后续状态。问题在于:
- teacher 的第 10 步推理,是在 teacher 前 9 步都按 teacher 自己的方式走出来之后才有意义;
- student 推理时,前缀很可能已经偏离 teacher;
- 一旦前缀偏离,teacher trace 后面的“反思”“回退”“验证”就不一定对应 student 当前局面;
- student 继续模仿,可能只是学会在错误局面里说漂亮的反思话术。
这就是 reasoning SFT 的 off-policy 本质:训练时监督的是 teacher 状态分布下的 action,部署时 student 访问的是自己的状态分布。
可以把它类比成学棋:
- 普通答案 SFT:背一道题的标准答案;
- reasoning SFT:背高手从开局到收官的完整复盘;
- off-policy 问题:你自己第 5 步已经下偏了,但还在背高手第 6 步的走法,这个走法在你的局面里可能完全不成立。
#3. 发展脉络:这个问题是怎样一步步被看见的?
#3.1 CoT / STaR 阶段:先把 rationale 当作可训练对象
早期 Chain-of-Thought 的成功说明:让模型写出中间步骤,确实能提升复杂推理。STaR(arXiv:2203.14465)进一步提出一个自举循环:模型生成 rationale,正确的保留,错误的在给定正确答案条件下再生成 rationale,然后继续训练。
这个阶段的贡献是:reasoning trace 成为了训练数据。
但它也暴露了一个问题:最终答案正确,不代表中间过程真的可靠;中间过程看起来合理,也不代表它是 student 自己能执行的策略。
#3.2 Process supervision / verifier 阶段:只看 final answer 不够
Let's Verify Step by Step(arXiv:2305.20050)代表了另一个转向:既然 final reward 太粗,那就训练 process reward model,给中间步骤监督。
这个方向把问题从“有没有 rationale”推进到“rationale 的每一步是否可靠”。但它仍然没有完全解决 off-policy:即使某个 teacher step 在 teacher 轨迹上是对的,它在 student 偏离后的状态上也未必是合适动作。
#3.3 Self-correction / reflection 阶段:反思不是魔法,反馈才是关键
Large Language Models Cannot Self-Correct Reasoning Yet(arXiv:2310.01798)指出,仅靠模型自己说“让我检查一下”并不可靠。反思要有效,通常需要外部反馈、verifier、工具执行结果或可检验的任务结构。
这对 Think SFT 很关键:如果 teacher trace 中充满 reflection / backtracking 文本,student SFT 之后可能学到的是“反思的语言形式”,而不是“什么时候真的应该回退、回退到哪里、怎样根据反馈修正”。
#3.4 RLVR / DeepSeek-R1 阶段:让 reasoning pattern 从 reward 中涌现
DeepSeek-R1(arXiv:2501.12948)把方向推向 RL:不用直接模仿人工 CoT,而是用可验证奖励 incentivize reasoning。模型在 RL 中涌现出反思、验证、长推理等行为。
这个阶段解决了 teacher trace off-policy 的一部分问题:训练来自 student 自己的 rollout,更接近部署时状态分布。
但它留下了 LUFFY 直接面对的新瓶颈:如果 student 初始探索能力太弱,纯 on-policy RLVR 采样不到有奖励的轨迹,训练就很难启动。
#3.5 LUFFY 阶段:off-policy trace 不是不能用,而是不能用朴素 SFT 吃
LUFFY 的关键贡献,是把问题从“off-policy trace 有害吗?”改写成:
off-policy trace 有价值,但应该作为 RL 中的 guidance,而不是作为逐 token imitation 的唯一目标。
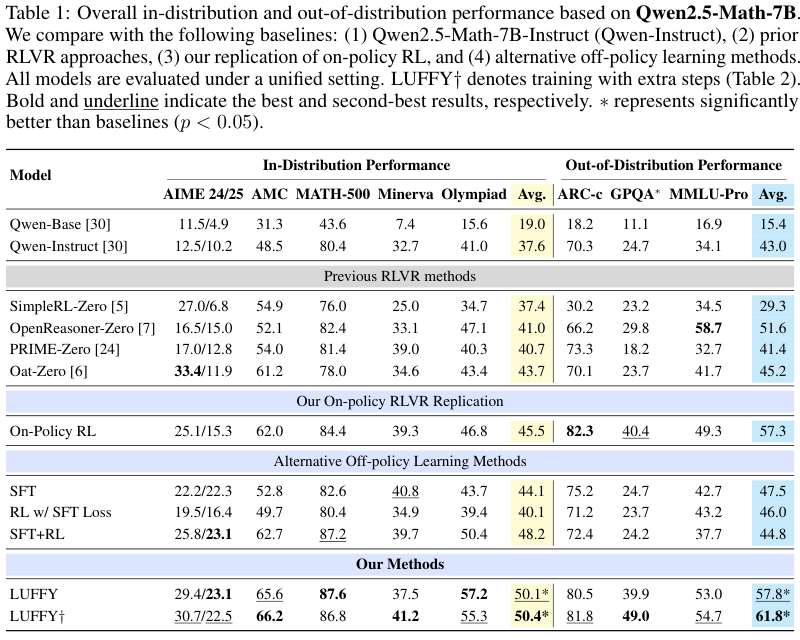
这其实是后续研究的分水岭:大家开始更系统地问,什么时候该模仿 teacher,什么时候该保留 student 的探索,什么时候该让 verifier / reward 来裁判。
#4. LUFFY 之后的主要研究路线
下面不按时间罗列,而按“它们试图修复 off-policy 问题的哪一面”来组织。
#4.1 路线 A:On-Policy Distillation —— student 去哪里,teacher 就在那里教
OPD 的核心定义很简单:
先让 student 自己生成轨迹 y ~ pi_student(.|x),
再让 teacher 在这些 student-generated prefixes 上提供 token / step / trajectory 监督。
这和普通 SFT / offline KD 最大的不同是:监督发生在 student 自己访问的状态上。
代表工作:
| 工作 | 时间 | 核心贡献 | 和 off-policy 问题的关系 |
|---|---|---|---|
| MiniLLM: On-Policy Distillation | 2023 / 2026 revision | 用 reverse KL 等方式做 LLM distillation,强调生成模型蒸馏中的分布问题 | 早期把 distillation 从固定 teacher 数据推向 student-generated outputs |
| GKD: On-Policy Distillation of Language Models | 2023 | student 生成输出,teacher 对 student 输出给反馈,学习 self-generated mistakes | 直接对应“student 在自己会犯错的地方学习” |
| Qwen3 Technical Report | 2025 | 报告中把 off-policy cold start 与 on-policy KL/logit alignment 结合 | 工业界把 OPD 作为 reasoning post-training recipe 的一部分 |
| Rethinking OPD | 2026 | 分析 OPD 成败条件:teacher/student thinking pattern 兼容,teacher 提供新能力 | 把“能不能学到”从 teacher 强不强推进到 teacher-student 分布是否兼容 |
| Revisiting OPD | 2026 | 指出 long rollout prefix drift、teacher support mismatch、token signal fragility | 明确诊断 student prefixes 偏离后 teacher guidance 不可靠 |
| Uni-OPD | 2026 | 从 student 探索 informative states 与 teacher supervision 可靠性两侧统一 | 把 OPD 问题拆成“学生探索”和“老师信号”两个瓶颈 |
OPD 可以看作 LUFFY 思想的一个更一般版本:LUFFY 是在 RLVR 中混入 off-policy guidance;OPD 则说,不管 teacher 是 logits、verbal score、rubric 还是 discriminator,都要尽量在 student 自己的分布上教。
但 OPD 也不是银弹。后续论文反复发现:如果 student rollout 已经偏得太远,teacher 在这些 prefix 上的 token-level KL 可能也会变得不可靠。换句话说,on-policy 只是把监督搬到了 student 分布上,但不保证 teacher 在这些状态上给出的每个 token 都值得模仿。
#4.2 路线 B:从 token-level KL 走向 calibrated / selective / relaxed distillation
标准 OPD 往往对所有 token 做 KL matching。但 reasoning 轨迹里不是每个 token 都同等重要:有些 token 是格式,有些是废话,有些才是真正决定后续路径的关键决策。
因此 2026 年出现了大量“校准 OPD 信号”的工作:
| 工作 | 核心问题 | 方法直觉 |
|---|---|---|
| REOPOLD / Relaxed OPD | 严格 imitation 会导致 negative transfer | 把 teacher-student log-likelihood ratio 解释为 token reward,选择性放松 imitation |
| SCOPE | 正确轨迹和错误轨迹不该同权 distill | 正确轨迹保留 student 行为,错误轨迹用 teacher-PPL 加权修复 |
| Entropy-Aware OPD | teacher 高熵时 reverse KL 容易过度坍缩 | 根据 teacher uncertainty 调整监督强度 |
| Best-of-N Teacher Rollout Selection | 单个 teacher rollout 可能噪声大、不匹配 student 当前行为 | 从多个 teacher rollout 中选择更适合的指导 |
| MOPD / Multi-Rollout OPD | 同一 prompt 的多个 student rollout 之间的信息被浪费 | 用成功 rollout 作为正例,失败 rollout 作为结构化负例 |
这些工作的共同趋势是:不要把 teacher token probability 当作无条件真理。
更准确的训练对象应该是:哪些 student states 是可修复的?哪些 student divergence 是有价值的?哪些 teacher feedback 在当前 prefix 下可靠?哪些 token 真正改变了决策?
这也是我觉得最值得继续挖的地方:从“teacher reliability”再往前走到“student learnability”。一个状态不只是老师会不会教,还要看学生当前是否学得动。
#4.3 路线 C:从 SFT / RL 二分走向 sparse-to-dense reward allocation
LUFFY 把 off-policy trace 放进 RLVR;OPD 把 teacher supervision 放到 student rollout 上。更近期的一类工作则在问:在 post-training 里,稀疏 reward 和密集监督应该怎样分工?
例如 Beyond GRPO and On-Policy Distillation(arXiv:2605.12483)提出一个 sparse-to-dense reward principle:
- 稀疏 verifiable reward 更适合用在强模型或有探索能力的模型上,让它发现更好行为;
- 密集 token-level teacher supervision 更适合把已经 reward-shaped 的行为压缩到小模型里;
- 数据和 reward 检查预算有限时,应该把可验证数据分配到最能产生边际信息的位置。
这和 LUFFY 的问题是同一枚硬币的两面:
- LUFFY 问:弱模型探索不够时,如何借强模型 trace?
- sparse-to-dense 问:如果强模型能探索,弱模型更应该直接 RL,还是接受 dense distillation?
对 reasoning SFT 的启发是:SFT 不是不能用,但应该明确它适合 cold start、格式对齐、能力压缩,而不是把它当成最终 reasoning policy learning。
#4.4 路线 D:backtracking / search trace training —— 错误有价值,但只有可诊断、可恢复的错误有价值
另一个相邻方向是让模型学习搜索、回退和反思。
代表工作包括:
- Stream of Search(arXiv:2404.03683):把搜索过程线性化成语言,让模型看到 fruitful mistakes 和 backtracking;
- Self-Backtracking(arXiv:2502.04404):让模型学习何时、何处回退;
- To Backtrack or Not to Backtrack(arXiv:2504.07052):比较 sequential backtracking 与 parallel best-of-N,在固定 compute 下分析何时顺序搜索真的有优势;
- How Much Backtracking is Enough? 等后续工作继续讨论 backtracking 的预算与收益。
这条线和 off-policy reasoning SFT 的关系很紧:很多 teacher CoT 中包含“等等,我错了”“让我们重新考虑”等反思文本。问题是,直接 SFT 这些文本未必让 student 真正学会搜索。
关键区别是:
- 表面 reflection SFT:学会说“我需要检查”;
- 搜索轨迹训练:学会在什么状态下识别错误、回退到哪里、换什么分支;
- RL / verifier-grounded backtracking:回退行为由可验证反馈或任务结构支撑。
因此,错误轨迹不是天然有价值。有价值的是:可诊断、可恢复、能暴露搜索结构的错误。
#4.5 路线 E:Agent / tool-use 中的 step-wise OPD —— token 级别太细,最终 reward 又太粗
当 reasoning 从数学题扩展到 tool-use agent、code agent、web agent,off-policy 问题会变得更严重。因为一个错误工具调用会改变外部环境,后续 token 全部进入新状态。
这时 token-level KL 更不够用。代表工作包括:
| 工作 | 场景 | 核心诊断 |
|---|---|---|
| TCOD | multi-turn autonomous agents | 多轮错误累积导致 trajectory-level KL instability,student 被推到 teacher 有效 support 之外 |
| SOD: Step-wise OPD | tool-integrated small agents | 错误工具调用会级联,后续 teacher token 监督越来越不可靠,需要 step-wise correction |
| Missing Old Logits in Asynchronous Agentic RL | 异步 agentic RL 系统 | rollout 生成和策略优化解耦会让 off-policy correction 的 old logits 语义错位 |
| Long-context reasoning recipe via GRPO + OPD | 长上下文任务 | SFT 稳但 exposure bias,GRPO on-policy 但 credit assignment 难,OPD dense 但不直接优化 reward,需要组合 |
这条线对 LLM Agent 尤其重要:agent 的“reasoning trace”不只是文字,而是包含 tool call、observation、subgoal、memory update、环境状态变化的轨迹。直接模仿 teacher 的完整 agent trajectory,比模仿数学 CoT 更容易 off-policy。
#5. 当前研究现状:共识、分歧和还没解决的问题
#5.1 已经基本形成的共识
第一,朴素 Think SFT 适合 cold start,不适合作为最终 reasoning 训练范式。
它能教格式、教基本解题风格、把模型拉到会输出长推理的区域。但如果一直靠 teacher trace CE loss,模型容易学到 teacher 的表面语言分布,而不是自己的可执行策略。
第二,on-policy distribution 很重要。
无论是 RLVR、LUFFY、OPD 还是 agent step-wise distillation,大家都在回到同一个原则:student 必须在自己会访问的状态上学习。否则训练时看到的状态和部署时遇到的状态不一致。
第三,teacher signal 需要校准。
teacher 强不代表每个 token 都值得模仿。尤其在 student prefix drift、工具调用错误、长上下文偏移、多轮 agent 环境变化之后,teacher 的 token-level guidance 可能不再可靠。
第四,dense supervision 和 sparse reward 是互补关系。
RLVR 给真实任务目标,但 reward 稀疏、credit assignment 难;OPD / SFT 给 dense signal,但可能 off-policy 或过度 imitation。后续趋势不是二选一,而是组合:先用 reward 发现行为,再用 dense supervision 压缩;或在 student rollout 上同时用 outcome reward 和 teacher guidance。
#5.2 仍然有分歧的问题
问题 1:teacher trace 到底应该在训练中扮演什么角色?
- SFT 视角:teacher trace 是标准答案;
- LUFFY 视角:teacher trace 是 off-policy guidance;
- OPD 视角:teacher 更像 student states 上的在线教练;
- verifier/RL 视角:teacher trace 不如 reward 可靠,trace 只是辅助探索。
我更认同 LUFFY + OPD 的中间立场:teacher trace 有价值,但不应该被当作无条件 imitation target。
问题 2:token-level KL 是不是合适的监督粒度?
数学 CoT 中 token-level KL 还能勉强工作;agent / code / tool-use 中,它往往太细。真正关键的是:选哪个子目标、调用哪个工具、是否回退、是否停止、是否保留某个解法分支。
因此更有前途的粒度可能是 step、subgoal、decision point、trajectory segment,而不是所有 <think> token。
问题 3:student divergence 是坏事还是好事?
传统 distillation 默认 student 偏离 teacher 是坏事。但在 code generation、数学题、agent task 中,student 可能走出和 teacher 完全不同但正确的路径。高 KL 不一定等于差;有时它是 productive divergence。
未来需要区分:
- 错误且不可修复的 divergence;
- 错误但可修复的 divergence;
- 正确但不同于 teacher 的 productive divergence;
- teacher 也不确定、应该交给 verifier 或搜索的区域。
#6. 一个更清晰的 taxonomy:off-policy reasoning training 可以分成四类状态
我觉得后续研究可以围绕 student 状态分布做一个更细的分类。
| student 当前状态 | 应该怎么训练 | 直觉 |
|---|---|---|
| Mastered state:student 已经会 | 少蒸馏或 self-distill,避免过度拉回 teacher | 不要把会做的题又教僵了 |
| Learnable boundary:student 接近会,但差关键一步 | 强 teacher guidance / process feedback / verifier critique | 最有价值的教学区,类似最近发展区 |
| Repairable bad state:student 走错但还能救 | backtrack、earliest-error critique、step-wise correction | 重点教“怎么救”,不是继续模仿后续 token |
| Unrepairable off-manifold:student 已经偏太远 | reset、重新采样、降低 KL 权重 | 在无意义局面里硬教会制造噪声 |
| Productive divergence:student 路线不同但正确 | 保留、强化、甚至反向蒸馏 | 不要用 teacher KL 抹掉多样正确解 |
这个 taxonomy 把问题从“teacher 强不强”推进到“student 当前状态是否可学、可修复、值得保留”。
这也是我认为 LUFFY 之后最有研究价值的方向:Learnability-Aware OPD / ZPD-OPD。也就是把“最近发展区”引入 reasoning post-training:训练信号应该集中在 student 能吸收、teacher 能提供增量信息、verifier 能确认收益的边界状态上。
#7. 对 LLM Agent / Code Agent 的启发
对你关心的 LLM Agent、code intelligence、self-evolving code agent 来说,这个问题会更关键。
数学题里的 off-policy trace 主要是文本推理分布错配;code agent 里的 off-policy trace 还包括:
- repo 状态不同;
- 测试结果不同;
- 工具调用顺序不同;
- 中间 patch 不同;
- 错误日志不同;
- agent memory / context 不同。
所以直接拿强 code agent 的完整 trajectory 做 SFT,风险非常高:student 可能学到的是“看起来像 agent 的操作格式”,而不是在自己实际会遇到的 repo 状态中做正确决策。
更合理的研究路线可能是:
- student 自己在 repo / benchmark 中 rollout,生成真实错误和真实中间状态;
- 用 test、static analyzer、compiler、verifier 判断结果;
- 让 teacher 只在关键决策点给 critique / patch suggestion / backtrack signal;
- 保留 test-passing 但不同于 teacher 的 productive divergence;
- 把 supervision 粒度从 token 提升到 step / edit / tool call / subgoal。
这会比“收集强模型 agent trace 然后 SFT”更接近真正的 self-evolving agent。
#8. 代表工作速查表
| 类别 | 代表工作 | 链接 | 关键词 |
|---|---|---|---|
| CoT 自举 | STaR | https://arxiv.org/abs/2203.14465 | rationale self-training |
| 过程监督 | Let's Verify Step by Step | https://arxiv.org/abs/2305.20050 | process reward |
| 自我修正诊断 | LLMs Cannot Self-Correct Reasoning Yet | https://arxiv.org/abs/2310.01798 | reflection reliability |
| OPD 早期 | MiniLLM | https://arxiv.org/abs/2306.08543 | reverse KL distillation |
| OPD 早期 | GKD / On-Policy Distillation | https://arxiv.org/abs/2306.13649 | self-generated mistakes |
| 搜索轨迹 | Stream of Search | https://arxiv.org/abs/2404.03683 | fruitful mistakes, search trace |
| RLVR | DeepSeek-R1 | https://arxiv.org/abs/2501.12948 | pure RL reasoning |
| backtracking | Self-Backtracking | https://arxiv.org/abs/2502.04404 | when and where to backtrack |
| backtracking 机制 | To Backtrack or Not to Backtrack | https://arxiv.org/abs/2504.07052 | sequential vs parallel search |
| off-policy guidance | LUFFY | https://arxiv.org/abs/2504.14945 | mixed-policy GRPO, policy shaping |
| 工业 recipe | Qwen3 Technical Report | https://arxiv.org/abs/2505.09388 | thinking mode, on-policy alignment |
| black-box OPD | GAD / Black-Box OPD | https://arxiv.org/abs/2511.10643 | discriminator as on-policy reward |
| verbal OPD | OVD | https://arxiv.org/abs/2601.21968 | verbal score instead of token KL |
| relaxed OPD | REOPOLD | https://arxiv.org/abs/2603.11137 | teacher-student ratio as reward |
| OPD failure modes | Revisiting OPD | https://arxiv.org/abs/2603.25562 | prefix drift, support mismatch |
| OPD mechanism | Rethinking OPD | https://arxiv.org/abs/2604.13016 | thinking pattern compatibility |
| calibrated OPD | SCOPE | https://arxiv.org/abs/2604.10688 | correctness-routed weighting |
| agent OPD | TCOD | https://arxiv.org/abs/2604.24005 | temporal curriculum, agent trajectory |
| unified OPD | Uni-OPD | https://arxiv.org/abs/2605.03677 | exploration + teacher reliability |
| step-wise agent OPD | SOD | https://arxiv.org/abs/2605.07725 | tool-call error cascades |
| multi-rollout OPD | MOPD | https://arxiv.org/abs/2605.12652 | peer successes and failures |
| systems off-policy | Missing Old Logits | https://arxiv.org/abs/2605.12070 | async agentic RL correction |
| sparse-to-dense | Beyond GRPO and OPD | https://arxiv.org/abs/2605.12483 | reward allocation principle |
#9. 最后的研究判断
如果把 LUFFY 看成一个分水岭,那么它之后的研究现状可以概括成三句话:
- 大家已经逐渐不满足于“强模型 CoT SFT”这个简单 recipe。 它能做 cold start,但不能解决 reasoning policy 的状态分布问题。
- 主流方向正在往 on-policy / mixed-policy / student-state supervision 迁移。 RLVR、LUFFY、OPD、step-wise agent distillation 都是在不同粒度上把训练拉回 student 自己会访问的状态。
- 下一步的关键不是“更多 teacher trace”,而是“更懂 student 状态的教学策略”。 哪些状态可学、哪些可修、哪些该放弃、哪些 divergent solution 应该保留,这些会决定 reasoning post-training 的上限。
对我来说,最值得继续做的研究问题包括:
- Learnability-Aware OPD:估计 student 当前状态是否处在可学习边界,而不是统一做 KL;
- Productive Divergence OPD:在 code/math 中保留高 KL 但 test-passing 的 student 解法;
- Repairability-Aware OPD:判断错误 prefix 是否还能救,能救则 critique,不能救则 backtrack/reset;
- Decision-Sufficient OPD:只蒸馏真正影响任务结果的决策点,而不是全部
<think>token; - Model-Based OPD:用 world model / verifier 想象边界状态,再让 teacher 在这些高价值状态上教学;
- Agent Step-wise OPD:把监督粒度提升到 tool call、subgoal、patch、memory update 和 trajectory segment。
所以,LUFFY 的意义不只是提出了一个算法。它更像是在提醒整个 reasoning post-training 社区:
推理能力不是靠背强模型的长答案背出来的,而是在模型自己的状态分布中,通过探索、反馈、修复和选择性蒸馏逐步长出来的。